
Understanding Data Structures
A Comprehensive Guide for Beginners
Introduction:
Welcome to the foundational elements of software development: Data Structures. This guide’s purpose is to introduce you to the core data structures that allow efficient programming and problem-solving. By understanding these data structures, you’ll be equipped to select the most appropriate one for your specific needs, enhancing the efficiency and effectiveness of your software solutions.
Table of Contents:
- What Are Data Structures?
- Arrays
- Linked Lists
- Stacks
- Queues
- Dictionaries
- Trees
- Graphs
- Selecting the Right Data Structure
1. What Are Data Structures?
Definition and Importance
Data structures are specialized formats for organizing, processing, retrieving, and storing data. They are critical for creating efficient algorithms and software applications. The choice of data structure directly impacts the performance of software in terms of speed, resource consumption, possibilities and scalability. By facilitating data arrangement in memory, data structures enable the implementation of complex algorithms and help manage and process data efficiently.
Understanding data structures is foundational for any software developer, as it allows for the optimization of code for performance and scalability. Different structures have unique strengths and weaknesses, making them suitable for specific tasks. For example, some are ideal for fast data retrieval, while others excel at data manipulation and traversal.
Overview of Types of Data Structures
Data structures can be broadly classified into two categories: Primitive and Non-Primitive data structures.
Primitive Data Structures: These are the basic data types provided by the programming language, such as integers, floats, booleans, and characters. They hold a single value and serve as the foundation for more complex structures.
Non-Primitive Data Structures: These are more complex forms of data organization that can store multiple items. Non-primitive data structures can be further divided into:
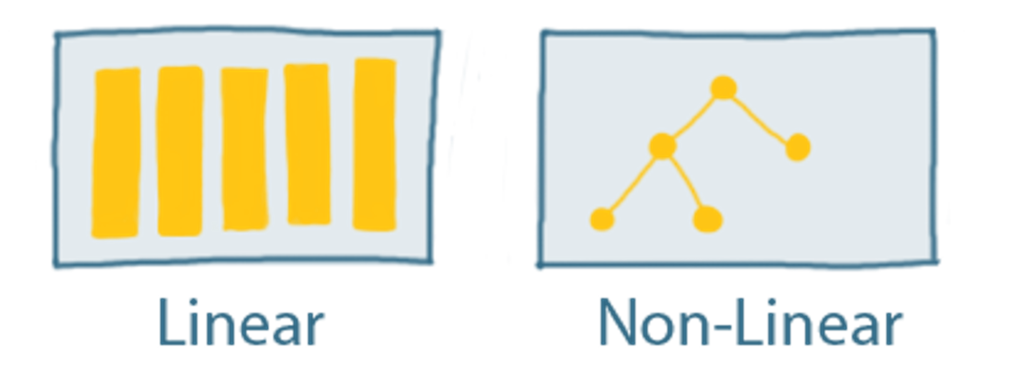
- Linear Data Structures (Data elements are arranged in a linear sequence): Arrays, Linked Lists, Stacks, Queues
- Non-Linear Data Structures (Elements are not arranged in a sequential order): Trees, Graphs, Hash Tables
2. Arrays
!https://cdn-images-1.medium.com/max/800/1*0YkEifUyCa99o8wM4gN2Nw.png
{kind=link}
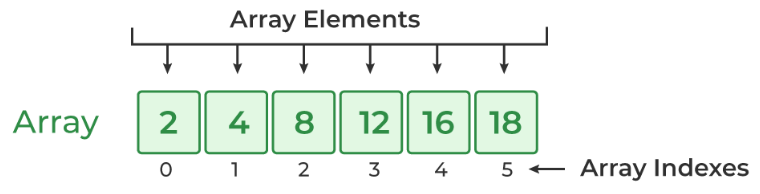
An array is a data structure consisting of a collection of elements, each identified by a index. Arrays store elements contiguously in memory, with each element being of the same data type. The direct access to elements via indices makes arrays efficient for lookups and fixed-size collections.
Characteristics:
- Fixed Size: Once declared, the size of an array is fixed and cannot be altered.
- Homogeneous Elements: All elements in an array have the same data type.
- Contiguous Memory Allocation: Array elements are stored in contiguous memory locations, allowing for efficient access.
Use Cases and Limitations
Use Cases:
- Storing and accessing sequential data: Arrays are ideal for storing data that needs to be accessed sequentially or randomly using indices.
- Temporary storage of objects: Useful for holding objects temporarily before processing.
- Lookup tables and inverses: Arrays can be used to implement lookup tables, commonly used in databases and searching algorithms.
Limitations:
- Fixed Size: The size of an array cannot be changed dynamically, which can lead to either wasted memory space or insufficient storage capacity.
- Homogeneity: Only data of the same type can be stored, limiting flexibility.
Basic Operations: Python Code Examples
Insertion
# Creating an array
arr = [1, 2, 3]
# Inserting an element at a specific position
arr.insert(1, 4) # Insert 4 at position 1
print(arr) # Output: [1, 4, 2, 3]
Deletion
# Removing an element by value
arr.remove(2) # Remove the first occurrence of 2
print(arr) # Output: [1, 4, 3]
# Removing an element by index
del arr[1] # Remove element at index 1
print(arr) # Output: [1, 3]
Traversing
# Traversing and printing each element
for element in arr:
print(element)
# Output:
# 1
# 3
Searching
# Searching for an element and returning its index
index = arr.index(3) # Find the index of the first occurrence of 3
print(f"The index of 3 is: {index}") # Output: The index of 3 is: 1
# Searching using 'in' to check if an element exists
exists = 5 in arr
print(f"5 exists in arr: {exists}") # Output: 5 exists in arr: False
2. Linked Lists
Linked Lists are a fundamental data structure consisting of a sequence of elements, each contained in a node. The node contains two items: the data and a reference to the next node in the sequence. This structure allows for efficient insertion and deletion of elements as it does not require the elements to be stored contiguously.
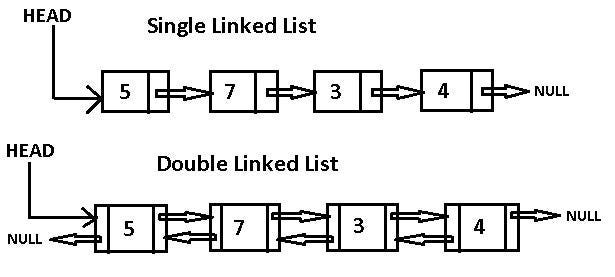
Introduction to Singly and Doubly Linked Lists
!https://cdn-images-1.medium.com/max/800/0*l2DH3tWYiaNAcbcB.jpeg
{kind=link}
- Single Linked Lists: Each node in a singly linked list contains a reference to the next node in the list. The list is traversed in one direction, starting from the head and moving towards the last node, which points to
nothing. - Double Linked Lists: Each node in a doubly linked list contains references to both the next and the previous node. This bidirectional traversal makes certain operations more efficient, as it can be navigated both forwards and backwards. The head’s previous pointer and the tail’s next pointer both point to
nothing.
Use Cases
- Undo Functionality in Text Editors or Forms
- Image Carousel or Sliders
- Dynamic Navigation Menus
- Playlist Management in Media Applications
3. Stacks
Stacks are a type of abstract data type that serve as a collection of elements, with two principal operations: push, which adds an element to the collection, and pop, which removes the most recently added element that was not yet removed. The stack operates on a Last In, First Out (LIFO) principle, where the last element added is the first one to be removed. This structure is analogous to a stack of plates, where you can only take the top plate off the stack.

Characteristics of Stacks
- LIFO Principle: The last element added to the stack will be the first to be removed.
- Access: Only the top element of the stack is accessible at any given time. Other elements below the top element cannot be accessed directly.
- Operations: The main operations are
push(add an element) andpop(remove and return the top element). Auxiliary operations may includepeek(return the top element without removing it) andisEmpty(check if the stack is empty).
Use Cases for Stacks
- Undo Mechanisms: In software applications, stacks are used to track actions for undo functionalities.
- Expression Evaluation: Stacks are used in algorithms that evaluate arithmetic expressions or validate syntax.
- Backtracking: Stacks can store previous states in algorithms that need to backtrack, such as pathfinding or puzzle solving.
Stack Implementation
class Stack:
def __init__(self):
self.items = []
def is_empty(self):
return not self.items
def push(self, item):
self.items.append(item)
def pop(self):
if not self.is_empty():
return self.items.pop()
return "Stack is empty"
def peek(self):
if not self.is_empty():
return self.items[-1]
return "Stack is empty"
def size(self):
return len(self.items)
Using the Stack
# Create a new stack
my_stack = Stack()
# Push elements
my_stack.push("A")
my_stack.push("B")
my_stack.push("C")
print(my_stack.peek()) # Output: C
# Pop an element
print(my_stack.pop()) # Output: C
print(my_stack.pop()) # Output: B
# Check if stack is empty
print(my_stack.is_empty()) # Output: False
# Pop the last element
print(my_stack.pop()) # Output: A
# Check if stack is empty again
print(my_stack.is_empty()) # Output: True
Queues
Queues are a type of data structure that operate in a First In, First Out (FIFO) manner. This means that the first element added to the queue will be the first one to be removed. Queues are particularly useful in scenarios where you need to manage objects or tasks in a sequential order.

Use Cases in Web Development
- Asynchronous Data Processing:
- Queues are ideal for handling asynchronous tasks such as sending emails, processing uploaded files, or generating reports. These tasks can be added to a queue and processed in the background without blocking the main application flow.
- Request Handling in Web Servers:
- Web servers use queues to manage incoming requests. Each request is placed in a queue and then processed sequentially, ensuring that resources are allocated efficiently and that each request is handled in order.
- Real-time Messaging Applications:
- In applications that feature real-time messaging or notifications, queues can manage messages or notifications before they are sent to users, ensuring that they are delivered in the correct order.
- Task Scheduling:
- Queues can be used to schedule tasks that need to be executed at specific times or after certain intervals. This is useful for routine database maintenance tasks, recurring data imports, or batch processing.
- Load Balancing:
- In high-traffic web applications, queues can distribute tasks evenly across multiple servers or workers, ensuring that no single server becomes overwhelmed, which improves the application’s scalability and responsiveness.
Python Example:
A simple queue implementation in Python using the queue module:
from queue import Queue
# Create a queue
q = Queue()
# Adding items to the queue
q.put('Task 1')
q.put('Task 2')
q.put('Task 3')
# Processing items in the queue
while not q.empty():
task = q.get()
print(f"Processing {task}")
q.task_done()
# Output:
# Processing Task 1
# Processing Task 2
# Processing Task 3
Dictionaries:
Dictionaries, also known as associative arrays or hash maps in other programming languages, are data structures that store key-value pairs. Keys are unique identifiers used to access corresponding values, making dictionaries ideal for representing relationships and data mappings in an easily accessible format.

Key Characteristics:
- Mutable: You can add, remove, or modify key-value pairs.
- Dynamic: Dictionaries can grow or shrink as needed.
- Indexed by Keys: Values are accessed using unique keys rather than sequential indices.
Use Cases in Web Development:
- Storting and Parsing Data:
- Use dictionaries to store user profile information, preferences, or settings, facilitating easy access and modification.
- When interacting with web APIs, responses are often JSON objects that Python can easily parse into dictionaries, simplifying the process of accessing specific data fields.
- Configuration Settings:
- Store configuration settings for web applications, such as database connection parameters or third-party API keys, in dictionaries for organized and centralized access.
- Template Rendering:
- In web frameworks like Flask or Django, dictionaries are commonly used to pass data to templates, allowing dynamic content rendering based on the values in the dictionary.
Python Example: Using Dictionaries
A simple example demonstrating how a dictionary can be used to store and access user profile data:
# Define a dictionary to store user profile information
user_profile = {
"username": "johndoe",
"email": "[email protected]",
"location": "New York",
"verified": True
}
# Accessing dictionary elements
print(f"Username: {user_profile['username']}")
print(f"Email: {user_profile['email']}")
# Modifying dictionary elements
user_profile['location'] = "Los Angeles"
# Adding a new key-value pair
user_profile['interests'] = ['coding', 'music', 'gaming']
# Removing a key-value pair
del user_profile['verified']
# Outputting the updated dictionary
print(user_profile)
Trees
Trees are a non-linear data structure consisting of nodes connected by edges, with one node designated as the root. Each node can have zero or more child nodes, forming a hierarchical structure. Trees are particularly useful in scenarios requiring hierarchical data representation or when performing operations that benefit from a hierarchical or organized dataset.

Use Cases in Everyday Web Development
- DOM (Document Object Model) Manipulation:
- The DOM in web pages is inherently a tree structure, with elements nested within one another. Understanding tree traversal and manipulation techniques is crucial for dynamically updating or querying web page content.
- Category and Subcategory Management:
- For e-commerce or content management systems, trees are ideal for organizing products or articles into categories and subcategories, allowing for efficient data retrieval and display.
- Comment Threads:
- Nested comment threads, such as those found in forums or beneath articles, can be represented as trees. Each comment with its replies forms a subtree, facilitating operations like displaying, adding, or removing comments.
Graphs
Graphs are versatile data structures that consist of a set of nodes (vertices) connected by edges. They can represent complex relationships and are widely used in various applications, including web development. Understanding and utilizing graphs can significantly enhance the functionality and efficiency of web applications by modeling real-world problems and relationships in a more natural and intuitive way.

Use Cases
- Social Networks:
- Graphs are foundational to social networking platforms, where users are represented as nodes, and relationships (friends, followers) are edges. This allows for features like finding connections, suggesting friends, and displaying news feeds based on user relationships.
- Recommendation Systems:
- Used in e-commerce and content platforms to recommend products, movies, articles, etc., based on user preferences and behavior. Graph algorithms can identify patterns and connections among users and items to generate personalized recommendations.
Selecting the Right Data Structure
When developing web applications, choosing the appropriate data structure can significantly impact your application’s performance, scalability, and maintainability.
Selecting Criteria:
When deciding on a data structure, consider the following criteria based on your web application’s needs:
- Performance Requirements: Evaluate the time complexity for insertion, deletion, access, and search operations. Choose data structures that offer the best performance for the most critical operations in your application.
- Memory Usage: Consider the space complexity and memory usage, especially if dealing with large datasets.
- Flexibility and Scalability: Assess how easily the data structure can adapt to changing requirements and scale with increasing data volume.
- Complexity of Implementation: Balance the complexity of implementing and maintaining the data structure against its performance benefits and flexibility.
Conclusion
The choice of data structure should be driven by the specific requirements of the web application, considering factors like the type of data, operations performed most frequently, and scalability requirements. By thoughtfully selecting the most appropriate data structure, web developers can ensure their applications are efficient, maintainable, and scalable.